Hi Readers,
Hope all are doing well,
I am going to talk about raspberry pi.
What is raspberry pi –
The Raspberry Pi is a series of small single-board computers developed in the United Kingdom by the Raspberry Pi Foundation to promote the teaching of basic computer science in schools and in developing countries.
A Raspberry Pi is a credit card-sized computer originally designed for education, inspired by the 1981 BBC Micro. Creator Eben Upton’s goal was to create a low-cost device that would improve programming skills and hardware understanding at the pre-university level. But thanks to its small size and accessible price, it was quickly adopted by tinkerers, makers, and electronics enthusiasts for projects that require more than a basic microcontroller (such as Arduino devices).
The Raspberry Pi is slower than a modern laptop or desktop but is still a complete Linux computer and can provide all the expected abilities that implies, at a low-power consumption level.
Need – sd card, card reader, monitor
Insrer sd card in card reader and connect cardreader to computer/laptop
fire command df –
check where your sd card is inserted
you need fire umount command from path where it’s mounted..NOTE- to format any device we need to unmount it first
like you need to umount /dev/mmcblk0px(x is any number) and path of /dev/mmcblk0px (x ia any number ) is /run/media/anandprakashdnyaneshwartandale/SETTINGS
then you need to fire command-
umount /run/media/anandprakashdnyaneshwartandale/root and
umount /run/media/anandprakashdnyaneshwartandale/SETTINGS
after fireing lsblk command you should be able to see – ‘mmcblk0’ path
like-
mmcblk0 179:0 0 29.7G 0 disk
├─mmcblk0p2 179:2 0 1K 0 part
├─mmcblk0p7 179:7 0 28.5G 0 part
├─mmcblk0p5 179:5 0 32M 0 part
├─mmcblk0p1 179:1 0 1.1G 0 part
└─mmcblk0p6 179:6 0 63M 0 part
After that you need to fire a command sudo mkdosfs -F 32 -v /dev/mmcblk0 to install format the device(sd card here)
sudo dd bs=1M if=”path to image” of=/dev/mmcblk0 status=progress
fire command sudo mkdosfs -F 32 -v /dev/mmcblk0 – to format your file system
if you are using fedora your path of sd card will be something like /dev/x/x/
if you are using ubuntu then path would be /media/x/x
I will talk about fedora,
so after formatting, you nned to install something onm that right?
so fire the command ‘sudo dd bs=1M if=”path/of/image/for/raspberrypi” of=/dev/mmcblk0 status=progress’
dd is use to convert and copy a file, you can see man pages of dd
then go to you sd card by cd command – in my case ‘cd /run/media/anandprakashdnyaneshwartandale/46ed1fb6-8b80-414d-b41a-e721d2b37b05’
there you can see filesytem etc,mnt,var,usr etc
go to etc of your sd card and append your internet connection in /network/interfaces fire
to make your raspberrypi system accessible by ssh, you need to make ssh enabled by adding following line in etc/rc.local (NOTE- etc is inside of raspberrypi system not your local)
IP=$(hostname -I) || true
if [ “$_IP” ]; then
printf “My IP address is %s\n” “$_IP”
fi
if [ -e /etc/SSHFLAG ]; then
/usr/sbin/update-rc.d -f ssh defaults
/bin/rm /etc/SSHFLAG
/sbin/shutdown -r now
fi
sudo /etc/init.d/ssh start
Then you need to check ip address of sytem mounted on sd card – how?
ans- just remove sd card reader , insert sd card in raspberry pi connect raspberry pi to any monitor and reoot it, if network is good you can see ip address of system installed on sd card in rasberrypi
you need to copy that ip.
now you rasberry pi is on-
and steps to get gui of raspberrypi sytem using tightvnc and vncviwer
open xterm on your system, enter ‘vncviewer’ command on xterm
then you will see pop up asking for ip address and port to connect using vncviewer
enter ip address of you raspberrypi and enter port it’s listening try port 1/2 as well
then you wiil get gui of sytem install on sd inserted in raspberrypi
you can ssh using ssh pi@ipaddressfound and password is raspberrypi
after successful of ssh you need to require packages related to python on that
i just fired command ‘apt-get install python-dev’
commect LED and to pins of raspberrypi like-
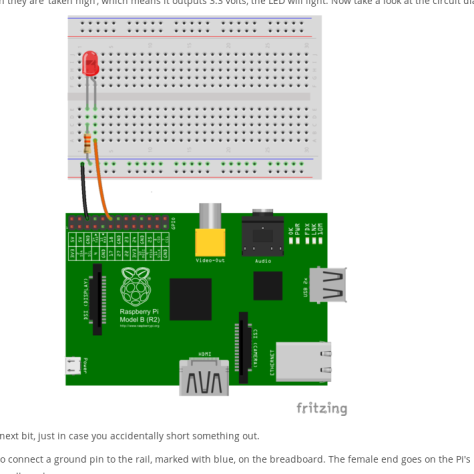
then fire command python3 on the seesion where you ssh to system installed on sd card inserted in raspberrypi
from RPi import GPIO as io
io.setmode(io.BOARD)
io.setup(16, io.OUT) – to get output from raspberry pi
io.output(16, io.LOW) – to turn off LED
io.output(16, io.HIGH) – to turn on LED
yeahhhhhhhhhhhhhhh, ver long blog but very interesting right?
so now you can do python programs to do ehatever you want to do with LED may be blinking design with many LEDS. so go for it, all the best.